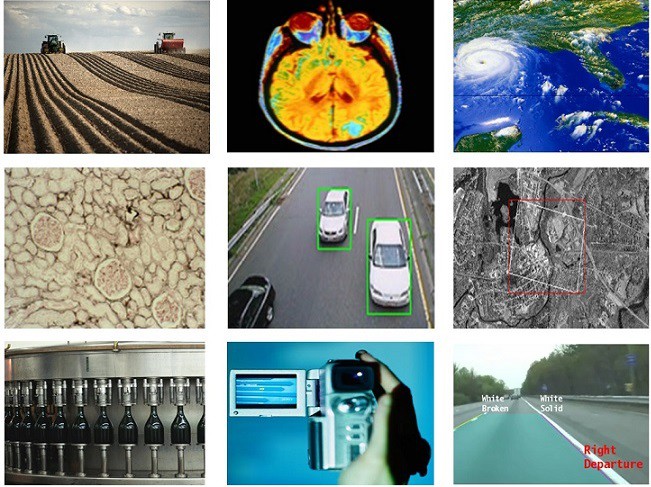
Strojové učení (2)
Stručný úvod k strojovému učení

Minulý příspěvek se věnoval chytré kameře připojené k Mikro:bitu a její využití. Na řadu dotazů tento příspěvek letmo uvádí téma "Strojové učení".
Strojové učení, (jak bylo minule uvedeno), patří do oboru umělé inteligence. Zařazení a další členění strojového učení poskytuje následující obrázek.
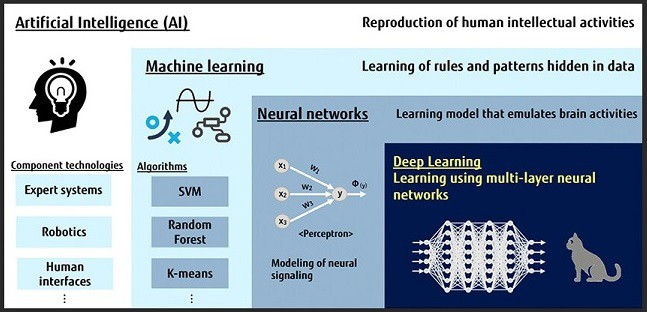
Kde se hlavně používá strojové učení?
Pro úkoly, které jsou příliš rozsáhlé (příliš hodně dat, časově náročné zpracování). Pro úkoly, které jsou příliš složité (velké množství proměnných, náročné pro klasické analytické řešení). Pro úkoly vyžadující rozpoznávání či už obrazu, zvuku, textu, signálu, atd. Pro úkoly, které se vyznačují neurčitostí, nepřesností, kde jsou stochastické projevy.
Hlavní metody strojového učení: prohledávání stavového prostoru, učení umělých neuronových sítí, posilované učení, Bayesovské učení (na základě podmíněné pravděpodobnosti), evoluční techniky, fuzzy učení, techniky rozhodovacích stromů, techniky rozhodovacích pravidel, techniky konceptuálního shlukování, usuzování na základě analogií, ...
Základní technikou (zjevně či skrytě) je prohledávání stavového prostoru. K charakteristickým rysům patří využívání znalostí, práce se symbolickými či strukturovanými proměnnými či aplikace moderních poznatků z oboru nestandardních logik. Úspěšně byly vyzkoušeny také algoritmy inspirované biologickými systémy. Dá se říci, že strojové učení patří mezi nejstarší disciplíny matematické informatiky. Další text bude věnován hlavně umělým neuronovým sítím pro jejích široké použití a stálý rozvoj.
Všechny algoritmy pro strojové učení pracují na automatickém nalezení takových transformací, které přeměňují data na užitečnější reprezentace pro danou úlohu. Podle toho, zda jsou využity znalosti o dané úloze či nikoliv, rozlišujeme algoritmy informované a neinformované. Pro řešení dané úlohy volíme takový algoritmus, který je nejefektivnější a postupuje přímočařeji k cíli.
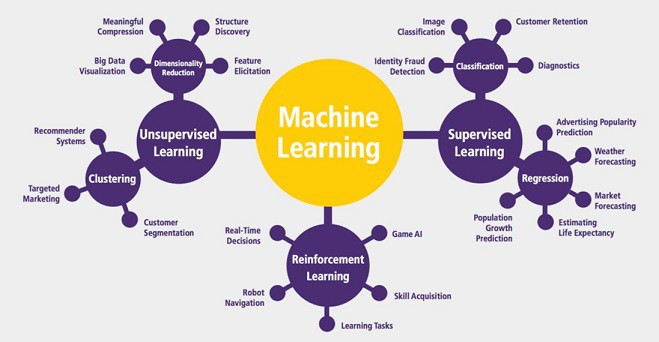
Rozsáhlou oblastí strojového učení je posilující učení (Reinforcement Learning), kdy systém zpracovává poskytnutá data a dostává průběžnou odezvu ( ocenění, třeba ve formě bodové odměny). A to podle toho, zda se mu výstup povedl dle našeho očekávání či nikoliv. Systém pak pokračuje v používání procesů které vedly ke správnému výstupu, a opouští či pozměňuje procesy, které produkovaly nežádoucí výstupy. To znamená, že si vytváří vítěznou strategii. Posilující učení se uplatňuje v různých úkolech od her, až po aplikace u autonomních robotů.
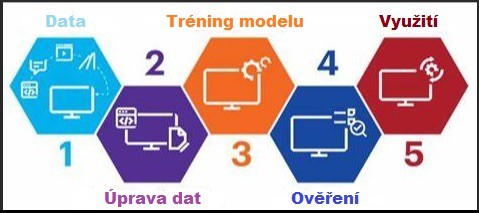
Obecný postup strojového učení umělých neuronových sítí
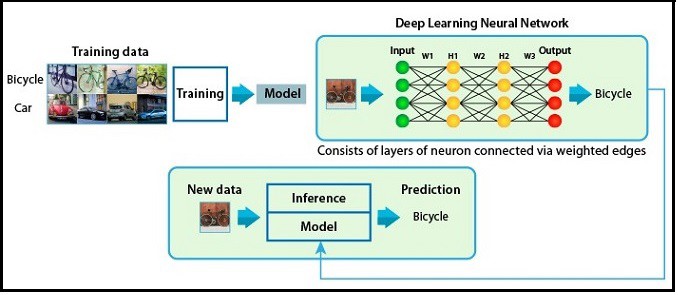
Shromažďování a příprava dat - algoritmus identifikuje zdroje a na základě sestavených dat vytvoří struktury. Data se rozdělí do dvou množin tréninkové a testované. Trénování vytvářejícího modelu - s využitím trénovací množiny dat dochází k vyladění na maximální rychlost a přesnost zpracování. Ověření modelu - za pomoci testovací množiny dat, která vyhodnocuje efektivitu algoritmu. Jakmile je algoritmus dostatečně odladěn lze pro dané úkoly získat interpretaci výsledku, jako jsou přehledy, závěry či předpovědi
Znázornění některých druhů strojového učení vytvořených pomoci umělých neuronových sítí
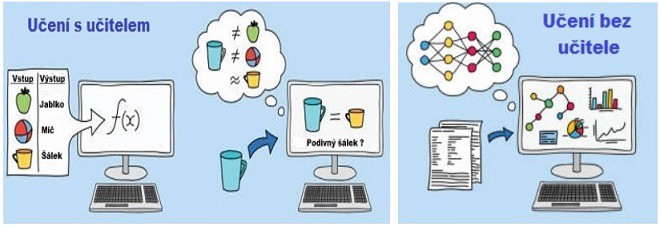
Při učení s učitelem (Supervised Learning) existuje nějaké vnější kritérium určující, který výstup je správný. Umělá neuronová síť učí srovnáváním aktuálního výstupu s výstupem požadovaným a přestavováním synaptických vah tak, aby se propříště snížil rozdíl mezi skutečným a žádaným výstupem. Metodika snižování rozdílu je určena učícím algoritmem.
Učení bez učitele (Unsupervised Learning) nemá žádné vnější kriterium správnosti. Algoritmus učení je navržen tak, že hledá ve vstupních datech určité vzorky se společnými vlastnostmi. Učení bez učitele je samoorganizací.
Zpětnovazebné učení převážně pro rekursivní filtry, jde o filtry u kterých kromě klasických vstupních signálů jsou na vstup přivedeny i některé výstupní signály. To znamená, že si mohou pamatovat potřebné hodnoty předchozích výstupů.
Hluboké učení (Deep Learning) je specifickou podskupinou strojového učení: nový přístup k učení se reprezentací z dat, který klade důraz na učení se stále smysluplnějších reprezentací pomoci více po sobě jdoucích vrstev. Počet vrstev přispívajících k modelu dat se nazývá hloubkou modelu. Metoda vychází z poznatků fungování lidského mozku.
Některé konkrétní oblasti využití
Rozpoznávání je rozhodováním na základě vstupního vektoru o tom, do které třídy (kategorie) předmět, daným vektorem popsaný, zařadit - obraz, hlas, text, ... Někdy se místo o rozpoznávání mluví o klasifikaci.
Shlukování (Clustering), kdy data seskupuje do skupin s podobnými vlastnostmi, ale bez znalosti obsahu. Například v medicíně analýza shluků identifikuje nemoci a jejich stádia. Hledání podobnosti výrobků od různých výrobců, ...
Predikce znamená předpovídání výstupní hodnoty jisté veličiny na základě jejího průběhu v minulosti. Příklady - předpověď zátěže v energetických oblastech, předpověď tvorby cen, předpověď poruchy v systému, ...
Filtrace vyhlazuje průběh vstupního signálu. Podstatou filtrace je získání úplného, šumem nezatíženého (nezkresleného) výstupního signálu ze signálu vstupního.
Detekce anomálií v různých procesech (při zpracování textových informací, při vyhodnocování signálů, atd.).